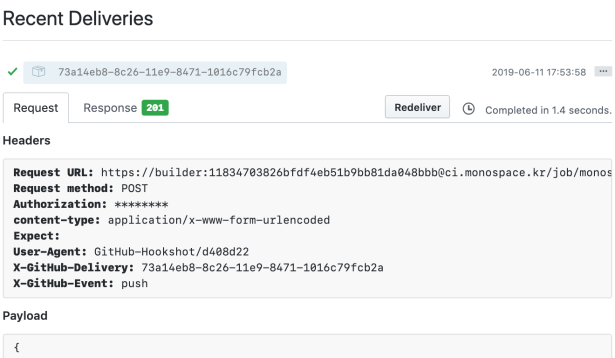
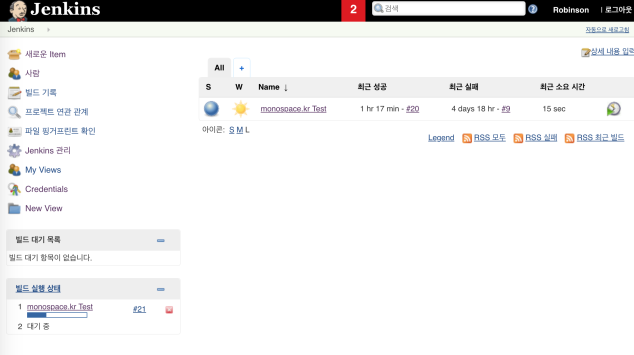
Git + Jenkins + Docker + S3 + CloudFront 를 이용해 간단한 React.js 기반 SPA를 자동 배포하는 시스템을 만들어 볼 것이다.
SPA는 static web hosting이 지원되는 어떤 플랫폼에 올려도 동작을 하기 때문에 다양한 배포 환경을 구성할 수 있다. Netlify 와 같이 SPA에 최적화된 CI/CD 및 호스팅을 제공하는 SaaS를 이용하거나, Google Firebase, Amazon S3 + CloudFront(CDN) 등의 static web hosting 이 지원되는 Cloud 기반 서비스를 이용하는 방법이 있는데, 이 글에서는 AWS S3 + CloudFront 방식을 진행 할 것이다.
AWS S3와 CloudFront 를 같이 사용하는 이유는 S3는 static web hosting 을 그리고 CloudFront 는 AWS Certificate Manager를 통해 생성한 SSL/TLS 무료 인증서를 설정해 HTTPS 환경을 구현할 수 있기 때문이다.
전체 과정을 요약 하면 다음과 같다.
- React 프로젝트 및 git 저장소 생성
- webpack 빌드 설정
- S3 버킷 및 CloudFront 설정
- 빌드 서버 설정
- Jenkins 설치
- 빌드 의존성 설치
- Jenkins 설정
- 빌드 스크립트 작성
- Github Webhook 과 Jenkins Build Trigger 연결
React 프로젝트 및 git 저장소 생성
먼저 배포를 할 샘플 SPA 앱을 만든다. 이 곳을 참조하여 만든 boilerplate를 이용해 가장 기본적인 수준의 React.js SPA 개발 환경을 생성한다.
배포 환경을 고려하여 webpack 설정을 바꾼다. webpack 설정은 공식 문서를 참조하였다. 기존의 webpack.config.js 파일 하나로 이루어진 설정 파일을 환경에 따라서 다음과 같이 나눈다.
- webpack.common.js
- webpack.prod.js
- webpack.dev.js
공통적으로 적용되는 부분은 webpack.common.js 로 따로 뺐다. 그리고 webpack.prod.js 와 webpack.dev.js 에서 webpack-merge 를 이용해 공통 설정을 불러와 머지를 지시킨다. 중복된 설정이 줄어들어 코드가 간결하다.
clean-webpack-plugin 과 html-webpack-plugin 를 –save-dev 플래그로 설치한다
둘의 용도는 다음과 같다.
- HtmlWebpackPlugin : webpack 빌드를 통해 생성된 bundle 을 로드할 html 파일을 생성 해준다. 파일명에 해시가 포함되어 빌드 시에 매번 파일명이 바뀌는 경우에 유용하다. 플러그인이 생성한 HTML 파일을 사용하거나, 템플릿 로더로 템플릿을 이용할 수 있다.
- CleanWebpackPlugin : 매 빌드 시 output 디렉토리를 비워준다.
디버깅을 위한 inline-source-map 을 설치한다.
./dist/index.html 파일을 ./src/assets/index.html 로 이동 시킨 후 webpack.common.js 설정에서 템플릿으로 지정해준다.
package.json 의 scripts 항목에 start 명령을 변경하고, build 명령을 추가한다.
{
"start": "webpack-dev-server --config ./webpack.dev.js",
"build" : "webpack --config webpack.prod.js"
}
dist 디렉토리가 빌드에 의해 동적으로 생성 되는 파일을 담는 목적으로 바뀌었기 때문에 .gitignore 에 dist 를 추가하여 형상관리에서 제외를 시킨다.
여기 까지 진행된 상태에서 git 에 저장소를 생성하여 소스를 push 한다. 현재 프로젝트 디렉토리가 boilerplate 의 저장소와 연결되어 있으니 우선 .git 디릭토리를 제거하고 git 초기화를 한 뒤 새로 생성한 저장소를 추가한다.
# 저장소 제거
$ rm -rf .git
# git 초기화
$ git init
$ git add .
$ git commit -m 'Initial commit'
# 새로 생성한 저장소 추가
$ git remote add origin git@github.com:devnoff/myProject.git
# 푸시
$ git push origin master
이렇게 git 저장소에 올려진 소스코드는 Jenkins 빌드 설정에 의해 빌드 서버에서 사용되고, 빌드가 요청 되면 git 으로 부터 내려 받아져 빌드 명령에 의해 dependancy 설치 등의 과정을 거치고 빌드가 진행된다.
위에서 작성된 코드는 다음 주소에서 확인할 수 있다.
Github : https://github.com/devnoff/myProject
S3 버킷 및 CloudFront 설정
S3, Cloudfront, ACM, Route53 를 이용해 HTTPS website 호스팅을 하므로써 운영 환경을 구축한다. 방법은 이 글을 참조
빌드 서버에서 AWS CLI 를 이용해 S3 에 빌드된 파일을 업로드 하고 CloudFront CDN에 재배포하는 과정은 빌드 스크립트 작성 부분에서 설명하겠다.
빌드 서버 설정
Jenkins 설치
Jenkins 설정 전 까지 다음의 과정이 선행 되어야 한다.
- EC2 Instance 추가
- NginX 설치, SSL 설정
- Docker 설치 – 설치 방법
- Dockerized Jenkins 설치 – 설치 방법
- 빌드 의존성 설치 : 배포할 React.js 앱의 빌드에 필요한 node.js 와 webpack 을 Jenkins 컨테이너에 설치
결과적으로 필자가 설정한 환경에서 Jenkins 는 맨앞단에 NginX 두고 reverse proxy 설정을 통해 443 포트와 docker 컨테이너의 외부 포트인 8080 을 연결해 주고, docker 컨테이너의 내부 50000 포트를 통해 실행된다.
443 → nginx → 8080 → Docker → 50000 → Jenkins
Nginx 와 reverse proxy를 사용하는 이유는 HTTPS 를 활성화 하고 내부망과 외부망에 대한 접근 권한의 달리 구성하여 보안을 강화하기 위함이다. 참조
빌드 의존성 설치
개발 환경과 버전을 일치하여 SPA 빌드에 필요한 다음의 의존성을 설치한다. (설치 방법은 생략)
- node.js
- webpack
Jenkins 설정
새 프로젝트 추가를 추가 한다. item name 으로 workspace 디렉토리가 생성 되는 점에 유의 한다.

OK를 누르면 프로젝트 설정으로 넘어온다. Github webhook 을 통해 payload 를 받으려면 매개 변수 설정이 필요하다. General 탭에서 다음과 같이 String parameter 매개변수를 추가한다


다음으로 소스 코드 관리 탭으로 이동해서 Git을 선택 후 저장소의 주소를 입력한다.
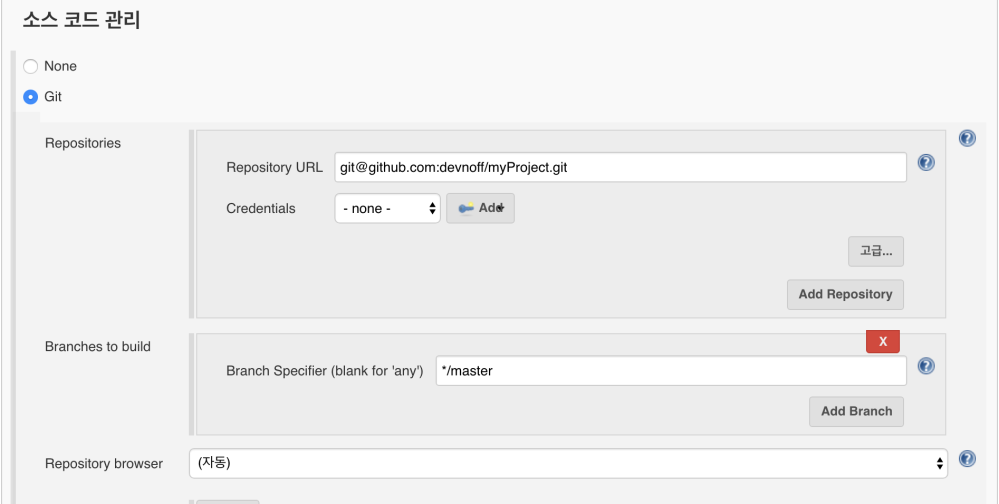
사전에 Jeknins 컨테이너의 id_rsa 공개키가 github 프로젝트의 Deploy Key 등록하는 과정과 github.com 의 RSA 를 추가하는 과정이 필요하며, 아래와 같이 저장소 접근 방식을 HTTPS로 바꾸고 github 자격증명 정보를 추가하는 것으로 대체할 수 있다.

그리고 자격증명을 위한 인증 정보를 Credentials 항목의 Add 버튼을 눌러 추가한다.

빌드유발(Build Trigger) 탭으로 넘어온다. 여러가지 빌드 유발 옵션이 있는데, 그 중에서 ‘빌드를 원격으로 유발’ 항목을 선택 한다. 이 항목은 Github webhook 과 연동하기 위한 설정으로 다음 챕터인 ‘Github Webhook 과 Jenkins Build Tigger 연결’에서 관련 부가 설명을 하겠다

빌드 탭으로 이동 후 ‘Add build step’ 을 눌러서 ‘Execute Shell’을 선택한다. Shell 명령을 통해 빌드를 진행 할 것이다. 빌드 스크립트를 한줄 한줄씩 작성해본다.

빌드의 전체 과정은 다음과 같다.
- dependency 설치
- 빌드
- s3 버킷 비우기
- s3에 빌드 결과물 업로드
- cloudfront resource 무효화
우선 package.json 상에 추가/제거된 의존성을 설치하는 명령어를 작성한다. 유의할 점은 아래 보는 바와 같이 실행 파일의 fullpath 를 다 적어주어야 한다.
# Dependency for SPA
/var/jenkins_home/.nvm/versions/node/v10.16.0/bin/npm install
그리고 webpack 빌드 명령을 작성한다. webpack 빌드 명령은 앞서 npm script로 만들어 둔 것을 이용한다.
# Build
/var/jenkins_home/.nvm/versions/node/v10.16.0/bin/npm run build
다음으로 배포할 S3 버킷을 비우고 빌드된 파일을 업로드하는 스크립트를 작성한다. (AWS CLI를 사용하기 위해서는 ~/.aws/config 에 자격증명 정보를 넣어 두어야하는데, 이 과정에 대한 설명은 생략한다.)
# Truncate Bucket
/usr/local/bin/aws s3 rm s3://monospace.kr --recursive
# Upload Build Artifacts
/usr/local/bin/aws s3 cp /var/jenkins_home/workspace/monospace.kr\\ Test/dist s3://monospace.kr/ --recursive
다음으로 CloudFront 배포 스크립트를 작성한다.
CloudFront 에 배포 할때 각 지역 엣지에 업데이트 된 소스코드를 반영하는 방법으로 invalidation 을 이용해서 캐시를 갱신 시키거나 default root object 를 변경해서 새로운 버전을 가리키도록 하는 방법이 있다.
invalidation(무효화) 을 이용하면 빌드 설정이 비교적 단순해 지지만 할당된 무료 캐시 무효화 횟수를 초과하면 과금이 되는 단점이 있고, root object 를 변경하는 방법은 빌드 설정에서 index.html 파일의 이름에 해시 또는 버전 식별자를 추가 하여 생성된 root file (ex. index.a34jgkh454j.html)을 CloudFront 배포 항목의 Default Root Object 이용하도록 해야 하기 때문에 빌드 설정이 다소 복잡 해지지만 별도의 비용이 들지 않는다.
예제에서는 Invalidation 방법을 이용하였다.
# CloudFront Invalidation
/usr/local/bin/aws cloudfront create-invalidation --distribution-id E135Y3KFO54CPN \\
--paths /index.html
완성된 스크립트는 다음과 같다
# Dependency for SPA
/var/jenkins_home/.nvm/versions/node/v10.16.0/bin/npm install
# Build
/var/jenkins_home/.nvm/versions/node/v10.16.0/bin/npm run build
# Truncate Bucket
/usr/local/bin/aws s3 rm s3://monospace.kr --recursive
# Upload Build Artifacts
/usr/local/bin/aws s3 cp /var/jenkins_home/workspace/monospace.kr\\ Test/dist s3://monospace.kr/ --recursive
# CloudFront Invalidation
/usr/local/bin/aws cloudfront create-invalidation --distribution-id E135Y3KFO54CPN \\
--paths /index.html
Github Webhook 과 Jenkins Build Trigger 연결
Jenkins 의 보안을 위해서는 CSRF(cross site request forgery) Protection 옵션을 화성화 해야하는데, 이 설정이 활성화 되어 있으면 github webhook 에서 jenkins 로 빌드 트리거를 실행 시 No valid crumb 에러가 발생한다. CSRF Protection 옵션을 끄더라도 Global Security 설정에서 Anonymous 에 대한 READ 권한이 주어져야 동작을 하게 되는데, 이 경우 외부에서 누구나 jenkins 를 열람할 수 있게 되므로 다른 방법이 필요하다.
사용자 추가 및 API 토큰 생성
원격으로 빌드를 실행하기 위한 사용자를 추가하고 사용자의 API 토큰을 이용하면 jenkins의 보안설정을 유지하면서 github webhook 을 받을 수 있다.
- 우선 사용자를 추가한다. 이 글에서는 builder 라는 이름을 썼다.
a. Jenkins > Jenkins 관리 > Manage Users 로 이동 한다.
b. ‘사용자 생성’ 메뉴에서 ‘builder’ 라는 계정명의 사용자를 생성한다.

- 그리고 builder 의 권한을 설정한다.
a. Jenkins > Jenkins 관리 > Configure Global Security 메뉴로 이동 한다.
b. Authorization항목에서 Matrix-based security 선택한다
c. ‘Add user or group’ 버튼을 눌러 아까 생성한 ‘builder’ 를 입력한다
d. ‘builder’의 권한을 다음과 같이 설정한다
> Overall : Read
> Job : Workspace, Read, Build
 결과적으로 이런 모습이 된다.
결과적으로 이런 모습이 된다.
- API 토큰 생성
a. 로그아웃을 한 뒤 ‘builder’ 계정으로 다시 로그인 한다.
b. 대시보드 좌측 ‘사람’ 메뉴에서 ‘builder’를 선택 후 좌측 ‘설정’을 눌러 설정 화면으로 이동 한다.
c. API Token 항목에서 ‘Add new Token’ 버튼을 눌러서 토큰 이름을 넣고 Generate 버튼으로 토큰을 생성한다.
 토큰 이름은 아무 것이나 해도 상관없다. 토큰을 사용할 때는 토큰 이름이 아닌 계정명을 함께 사용한다.
토큰 이름은 아무 것이나 해도 상관없다. 토큰을 사용할 때는 토큰 이름이 아닌 계정명을 함께 사용한다.
- 빌드 트리거 설정
대시보드에서 프로젝트를 선택하고 ‘구성’ 메뉴로 들어간다. 그리고 ‘빌드 유발’ 항목에서 ‘빌드를 원격으로 유발’은 이미 선택해 두어서 활성화 되어있다.

예제 에서는 helloworld 라고 토큰을 입력하였다. 실제 사용 시에는 사람이 읽을 수 없는 해싱된 문자열을 사용하는 것이 좋다. 아래에 예시에서 보는 것 처럼 URL을 통하여 빌드를 유발시킬 수 있다. 필자가 테스트로 구현 중인 jenkins URL을 기준으로 다음과 같이 되겠다.
<http://ci.monospace.kr/job/monospace.kr%20Test/build?token=helloworld>
하지만 이대로 URL을 호출하면 앞서 언급한 것과 같이 No valid crumb 에러가 뜬다. 이대로는 github webhook payload 설정에 넣을 수 없다.
생성한 계정과 토큰의 사용
이제 앞에서 만든 builder 계정과 API 토큰을 이용할 차례다. Jenkins Host 주소 앞에 :@ 형식으로 인증 정보를 전달하면 정상적으로 빌드가 되는 것을 확인할 수 있다.
https://builder:114bf74b38dde25c8bc7db803785cdf432@ci.monospace.kr/job/monospace.kr> Test/buildWithParameters?token=helloworld
Github webhook 설정
Github 프로젝트의 설정 페이지에 Webhooks 메뉴로 들어가서 ‘Add webhook’ 버튼을 눌러 웹훅을 생성 페이지로 이동 한다.

앞서 생성한 빌드 트리거를 Payload URL 에 넣는다. 아래에 설정 중에 글에는 다루지 않았지만 필자가 Jenkins를 구동 중인 서버는 NginX에 SSL 인증서를 설치하여 HTTPS 활성화 해두었기 때문에 SSL verification 을 사용하는 것으로 설정 하면 되지만, HTTPS를 지원하지 않는다면 Disabled 로 해두어야 동작한다. (물론 실제 운영 환경이라면 반드시 SSL verification 을 활성화 해야한다.)
그 아래로 어떤 이벤트로 웹 훅을 유발 시킬 것인가에 대한 설정이 있는데, 상황에 맞게 적절하게 설정하면 되겠다. 여기서는 푸시가 되었을 때 웹훅을 유발 하도록 설정하였다.
이제 아래 초록색 ‘Add webhook’ 버튼을 눌러 완료한다.


이제 모든 단계가 완료되었다. 이제 로컬 개발 환경에서 SPA 소스코드를 수정한 뒤 push 를 해보자.